TCAMと同等以上の性能をソフトウェアで実現したBGPルータ@Interop Tokyo 2018
Interop Tokyo 2018のShowNetバックボーンにて、NTTコミュニケーションズが開発したBGPルータ「Kamuee」が展示されています。 Kamueeは、TCAMと同等以上の性能をソフトウェアで実現できるという特徴があるとのことでした。
Kamueeの特徴は、非常に多くの経路情報が登録された状態で、高性能なパケット転送処理ができるというものです。 これまでも、経路情報が多数登録されていない状態であれば、DPDKの活用のみでソフトウェアによる高速なパケット転送に対する取り組みは過去に既に存在してました。 Kamueeが面白いのは、フルルート(Full route。IPv4が約70万プレフィックス、IPv6が約6万プレフィックス)を扱いながらも、高速なパケット転送が行える点です。 インターネット全体を示す地図ともいえるフルルートを扱うデータを圧縮することによって、CPUキャッシュに全部収めてしまったことがKamueeであるとも言えそうです。

写真:Kamueeの説明をする小原氏
高速な処理を必要とするネットワーク機器のためにTCAM(Ternary Content-Addressable Memory)という部品があります。 TCAMは、ビットが「マッチしている」「マッチしていない」「気にしない」という3種類のマッチングを行うための電子部品で、ネットワーク上のスイッチでサブネットマスクを考慮しつつ経路ルックアップなどを高速に処理するために搭載されます。 (TCAMとBGPルータについては、去年に書いた「Google誤設定によるインターネット障害とBGPルータのメモリ問題」もご覧ください。
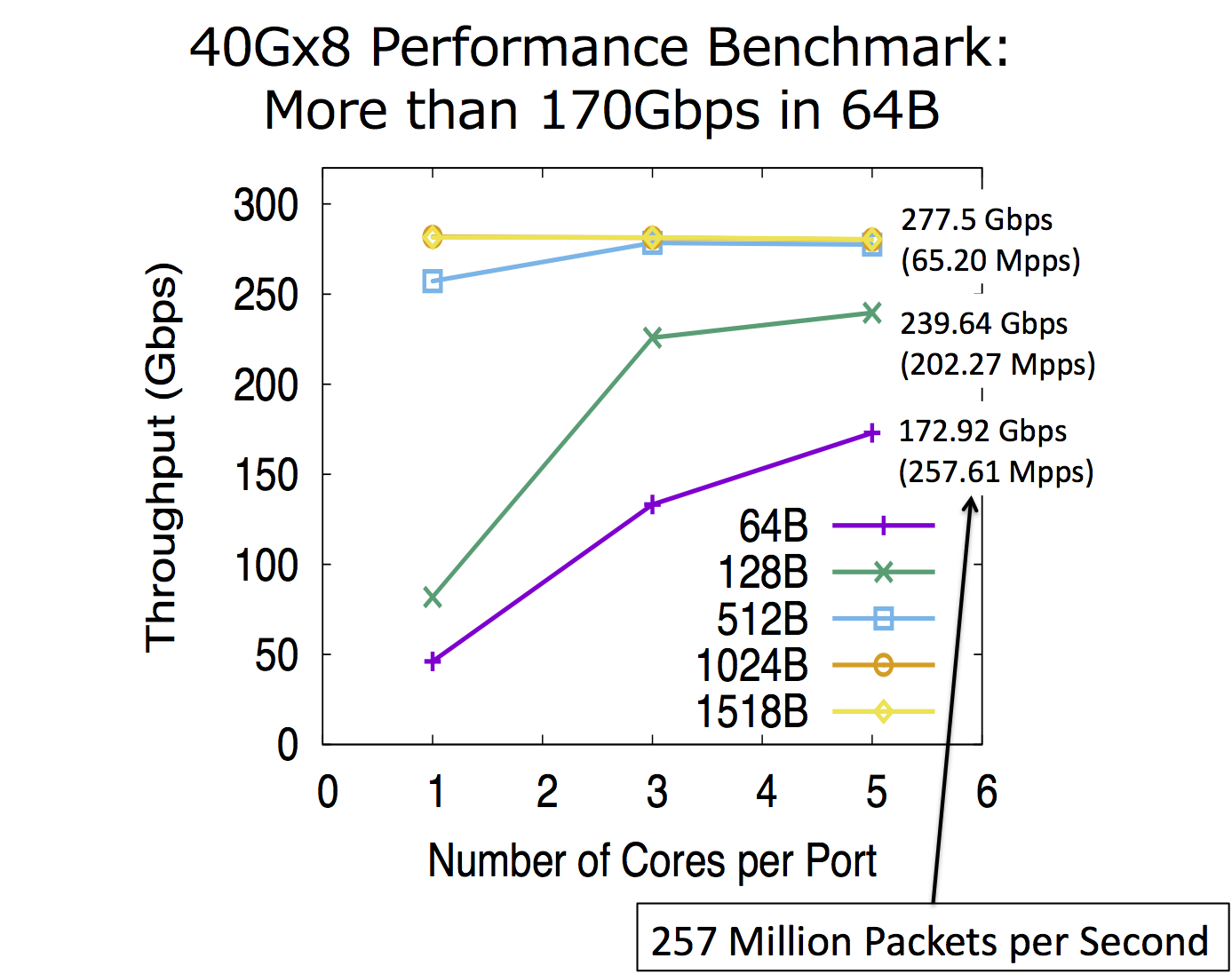
Kamueeは、「TCAMと同等以上の性能をソフトウェアで実現できる」とのことでした。 TCAMは1サイクルでの経路ルックアップを保証しますが、TCAMが200Mhzで稼働する場合、1秒あたりの最大ルックアップ回数は200M回です。 ベンチマークでは、Kamueeで、1秒あたり最大257Mパケットを処理できたことをもって、「TCAMと同等以上」という発表が行われていました。
Kamueeは、Linuxをベースに実装されています。 ルーティングプロトコルをQuaggaで行い、パケットフォワーディング部分などでDPDKを利用しています。
フルルートをCPUキャッシュに収めることの意味
Kamueeは、フルルートをCPUキャッシュに収めることによって高速な経路ルックアップを実現しています。
まず、参考までに、64オクテットデータを運ぶイーサネットフレームというショートパケットで100Gbpsの性能を実現することを考えると、148.8Mpps(packet per sec)になります。 148.8Mppsでは、イーサネットフレームひとつあたりの処理時間は約7ナノ秒になります。
GoogleエンジニアであるJeff Dean氏が2012年にまとめている各種遅延には、以下のように書かれています。 メインメモリを参照するのは、CPUキャッシュを参照するのと比べると圧倒的に遅いです。
| L1 cache reference | 0.5 ns |
| L2 cache reference | 7 ns |
| Main memory reference | 100 ns |
今回、Kamueeで使われている機材でのCPUキャッシュ参照にかかる時間は、上記値とは異なりますが、メインメモリ参照がCPUキャッシュ参照と比べて著しく遅いことは変わりません。 (Intel 64とIA-32アーキテクチャのCPUでの値(単位はサイクル)は、「Intel 64 and IA-32 Architectures Optimization Reference Manual」のp.54参考にしてください。)
100Gbpsの性能をPCアーキテクチャの機材で稼働するソフトウェアで実現するために、CPUキャッシュに収めることが非常に大事なのです。 そして、CPUキャッシュに収まるようなサイズに経路情報を扱うデータを圧縮して収めることで高速化ができるのは、メインメモリからの読み込みが頻繁に発生しないからなのです。
なお、経路情報を扱うデータが十分に小さいのであれば、Kamueeの特色がそこまで出ない可能性があります。 フルルートのように経路数が多い状態であっても、CPUキャッシュに収まるぐらいにデータを圧縮しているという点が、Kamueeが他システムと比べて有意な点であると思われます。 そういう意味で、ShowNet 2018でのデモもフルルートを扱うBGPルータなのだろうと思います。
TCAMと同等以上の性能を実現するPoptrie
Poptrieは、経路ルックアップのためのlongest-matchをTCAMと同程度の性能で実現するとのことでした。 200Mhzで稼働するTCAMの1秒あたりの最大ルックアップ回数は200M回程度ですが、Poptrieはそれと同等の性能をソフトウェアで実現するようです。
Poptrieの特徴は次の2点です。
- 1)処理コストの削減
- 2)処理に必要となるデータの大幅な圧縮
1)は、マルチウェイトライを拡張することにより、パトリシアトライ(別名ラディックストライ)と比較して、ルックアップ回数を大きく削減しています。 2)は、データを圧縮する各種技術によって、パケット転送時に必要となる経路表をCPUキャッシュに収めることができます。
小原氏によると、Linuxの通常カーネルでパトリシアトライのために利用されるメモリは100MB程度になるとのことでした。 その一方で、IPv4フルルート約70万プレフィックスを扱うためのPoptrieデータは3MB程度だそうです。 これにより、経路ルックアップに必要な検索用のデータ構造をCPUキャッシュに収めた状態で処理されるため、超高速な転送を実現しています。
ここでは詳細は割愛しますが、Poptrieは、複数のデータ圧縮テクニックを組み合わせています。 たとえば、64ビットアーキテクチャのCPUでNULLを表現するために64ビット使ってしまうところを、NULLを表現する部分をカットするという方法があります。 Poptrieでは、子ノードが存在する部分だけで1次元配列を作るのですが、子ノードが存在するかどうかに関して1次元ビット列で扱い、ビットが1になっている個数を数えるpopcntというCPU命令を使って、NULLとなる部分を排除した子ノードの1次元配列を作ります。 popcnt命令を使うという特徴は、Poptrieという名前の由来でもあります。 このほか、経路表に対してrun length的な圧縮も行うことで、さらにデータ容量を削減しています。
小原氏は私と同じ大学研究室の出身です。一昨年ぐらいに、小原氏にPoptrieの論文がACM SIGCOMMを通ったという話は聞いていました。 Poptrieが凄い技術であり、それを発明した浅井氏は本当に天才だという話を何度か小原氏から聞いています。 Poptrieは、当時東大の教員であった浅井氏(現PFN)と、NTTコミュニケーションズに勤める小原氏が共同で論文にまとめています。
今回、Kamueeの実装は、小原氏が中心になって行っています。 小原氏は、学部時代の卒論でzebra(現quagga)のospf6dを書いてます。 IETFで「OSPFv3のコードをスクラッチから書いた」という発表もしてました。 昔からTCP/IPスタックまわりの実装を行っており、その経験がKamueeの実装でも活かされているようです。
DPDKの効果的な活用
Kamueeは、Intel社が開発したDPDKを利用しています。 DPDKは、カーネルをすっ飛ばしてNICからアプリケーションが直接パケットを扱えます。 DPDKでは、NICに対してCPUコアを割り当てて、そのNICでのパケット受信をポーリングできます。 カーネルの割り込みやコンテキストスイッチを発生させないことで、高速な処理が可能となるというものです。
Intel社のDDIO(Data Direct I/O)もKamueeで活用されています。 DDIOは、NICで受け取ったパケットをそのままCPUキャッシュへと書き込むことができます。 高速な転送を行うためには、CPUキャッシュ内に存在しているパケットのデータがコピーされずに転送されるようにすることも大きなポイントです。
Kamueeは、個別のパケットの転送処理を一つのCPUコアで完結して行うRun-to-completionモデルを採用した設計で実装されています。 Run-to-completionモデルでは、パケットは受信処理から経路検索、ネクストホップへの送信処理までを同一のCPUコアが行います。 これに対して、Run-to-completionモデルでない方式では、一つのパケットについて、受信処理を行うコアと送信処理を行うコアが異なる、などが例として挙げられます。
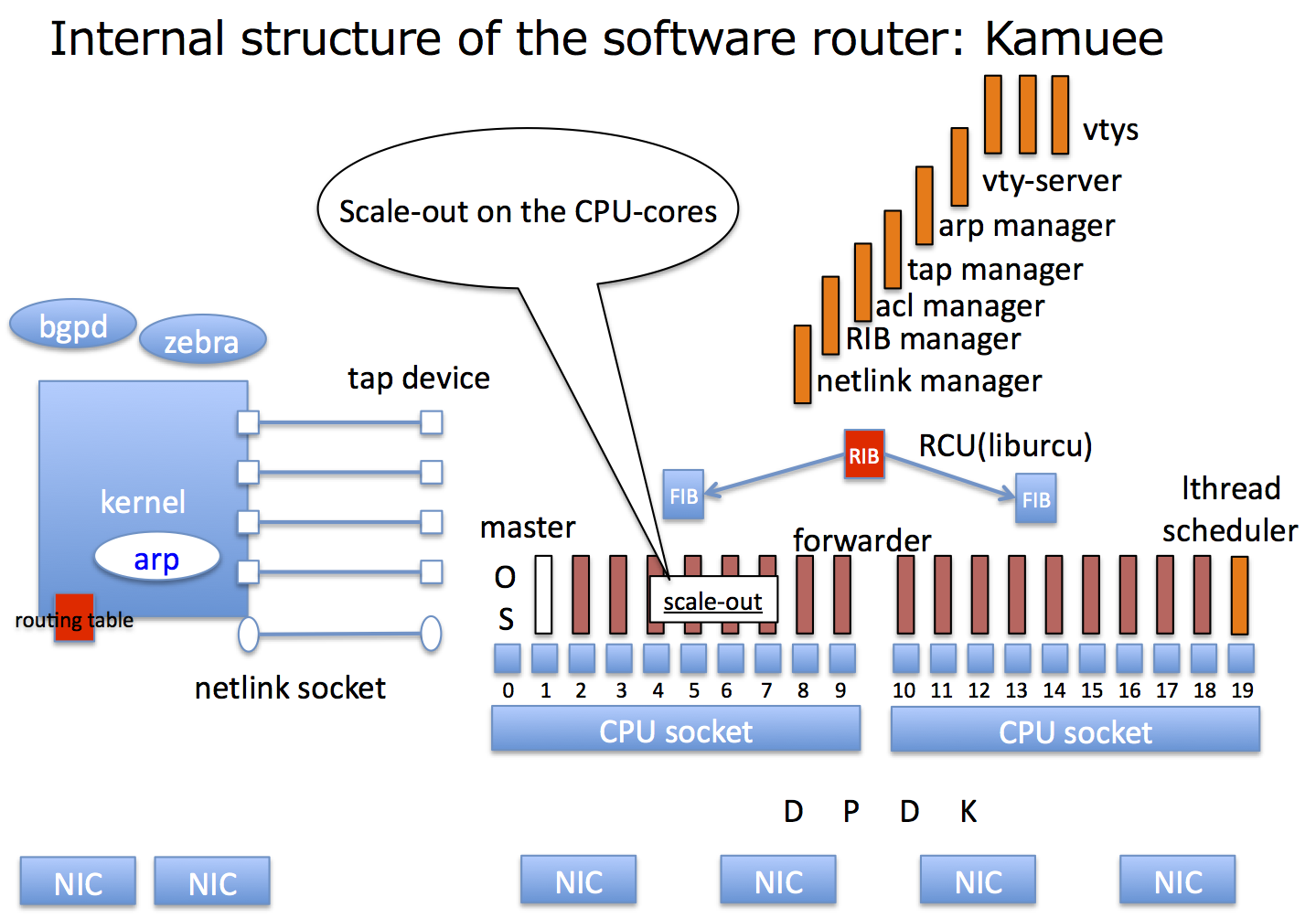
Run-to-completionモデルは、CPUコア毎に処理が完結するため、CPUキャッシュ汚染が少ないと言われています。 DPDKでは、高速処理を実現するため、Run-to-completionモデルが推奨されており、Kamueeもこの方式を採用しています。
Run-to-completionモデルは、パケット処理を複数のCPUコアに分散させることできるため、スケールアウトを行いやすいという利点もあります。 個々のパケット処理にかかる時間を、先ほど示した約7ナノ秒よりも遅い時間で行っていたとしても、複数のCPUコアで並列処理を行うようにすれば、100Gの性能を出せるようになるというのも、今回のポイントだろうと思います。
Interop Tokyo 2018での試み
Kamueeの中心的な技術であるPoptrieの論文は2015年に発表されています。 Poptrieに関連する発表は、その後、日本国内でも数回行われています。
ただ、過去の発表は、各種ルータとしての機能をそなえて実運用を行えるという段階ではなく、研究発表という要素が強かったようです。
Interop Tokyo 2018でのお披露目は、複数ポートの100GbEでフルルートを扱えるソフトウェアルータとして実際に運用に使えることを実証しつつのお披露目ということのようです。
最近のエントリ
- ShowNet 2025のルーティングをざっくり紹介
- RoCEとUltra Ethernetの検証:ShowNet 2025
- ソフトルータ推進委員会のスタンプラリー
- 800G関連の楽しい雑談@Interop Tokyo 2025
- VXLAN Group Based Policyを利用したマネージメントセグメント
- ShowNet伝送2025
過去記事
