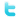Interview - Mark Townsley, IETF homenet working group chair

I had a chance to interview Mr. Mark Townsley (Cisco), co-chair of IETF homenet working group (April 3, 2013).
The homenet working group focuses on home networks with IPv6. The task of the working group includes producing an architecture document that outlines how to construct home networks involving multiple routers and subnets, i.e. multihoming with IPv6.
Since, "IPv6 multihoming issue" is one of the hottest topic here in Japan, I felt that the discussion made in homenet working group is very interesting.
-- (Interview started)
My name is Mark Townsley. I've been in Cisco for about 15 years, before that I've been doing stuff with communications since I was a kid.
At Cisco, the first protocol I worked on was L2TP. RFC2661 was authored by me, and I wrote much of the code since I was a software engineer in my first project at Cisco. And I also scaled the infrastructure because when we first did L2TP, it was our first use of virtual access interfaces at that level of scale. So, the IDBs(Interface Descriptor Block) in the routers couldn't scale very much, so I had to teach our routers how to scale the virtual router interfaces into the L2TP protocol. That was the first big thing I did at Cisco.
And then, after that, I was working group chair of L2TP working group, and later became the Internet area director. 2005 to 2009 I think. It was 2 terms. During this time I created the softwire working group and a few others.
And then, after that period, It was right about the time IPv4 exhaustion was becoming serious in peoples minds, so I focused my attention on that. I've been working throughout the industry to see IPv6 deployed and create real business cases for service providers. And to move the industry to IPv6. That was my focus from 2009 to 2010, and the past 3-4 years.
That's me :)
Q: My first question is about the homenet working group. So, tell me about that and what is happening at the IETF.
The homenet working group was created in 2011. It wasn't just me but I kind of pull together a group of people to form a working group with a particular scope.
You can see from the statistics that native IPv6 as well as 6rd based IPv6 or even L2TP or PPP based IPv6, are really starting to deploy to residential edge. But you can not see what to do after, because in the past there has always been this "NAT" :-(. In the IPv4 world, the service providers saw the home as one PC. We created this NAT box to create a network behind it, and fake everything up, make it look like one PC. I felt like it is a big shame if we did the same thing with IPv6.
Now, we have to make the home, a "REAL" end-to-end network. Make it part of the internet, rather than a separate thing on the side.
So, that's the main part of the mission state of the home network. The homenet being in the internet area, is focused mostly at layer 3, plus or minus a little. .We have routing, service discovery, etc. But the main point is, "IPv6 is coming to the edge, how do we get it to work in the home.
And also, in the process we would like to make the home network better. Because right now, it's really a house of cards. Sometimes it works, sometimes it doesn't. We're pretty okay as an industry, getting a device in a home to reach the internet. But when it comes to reaching other devices in the home, sometimes it works, and sometimes it doesn't. Although it's not the only reason, lot of the times, it is because there is a NAT and a NAT and a NAT in IPv4.
So, we are really targeting anything within that home network, and we want to be able to basically enable any number of routers and devices to be arbitrary connected in the home.
We thought about this, and we still have a group of people who thinks, it's too higher goal, to have arbitrary connection. They want to support a more simple topology, with a few routers, one main ISP, forming a tree.
The problem with that from my perspective, and I believe it reamins the working group consensus at this point, is that it's too much to ask a customer to plug things in a certain way. It might be okay if you can predict the failure cases, but once you are thinking of all the failure cases, you end up with something that is more and more complex. And, from the beginning, if you say, "okay, you can connect anywhere you like", it would be easier. So, any way, any loops, any where you want, between your routers.
Q: The visions and issues you have just mentioned, are those the working group issues or is it your individual point of view ? Rather than resorting to the tree structure, sounds like intersecting the network link in a fabric way. Will that mean homenet working group will be creating something like ethernet fabric, or maybe something like FabricPath in the home network?
It's like the networks we see today. I believe the the home network is becoming more like the campus networks that we have today. It's just that the home network needs to be more automatic, because there is no operator.
There are some that share this view, and even go beyond saying that the home network should be able to automatically connect with neighbors, provide transit for them to various ISPs or for direct connectivity, etc. Others in the working group try to limit the network to one type of topology or another and. So, you get both groups, and at the moment the consensus of the Working Group is somewhere in the center of the two.
It boils down to like a classic debate, "are you trying to achieve a short time goal or a long time goal ?". And that's what the group is sort of like wrestling right now.
We had a proposal from some of the cable operators, at just the last IETF, which has the case for the more limited topology. Before that IETF meeting, there were pretty strong consensus among the people talking in the working group that there will be an arbitrary connectivity.
The reason I bring this up right now is that, it is the current issue, and will likely be discussed between now and the next IETF meeting. On February 20th, a week before the last IETF, there was a brand new document from the group of operators that were working in a group outside of the IETF.
The document was very thorough, with a full solution and prototype running code to go with it. It took some in the Working Group by surprise, and I believe they wished that the operators had worked within the IETF rather than outside. In any case, it higlights the difference between how a network operator sees the residential network evolving versus how an end-user sees it. The limit from the operator’s perspective seems to be that the user can have one two or maybe three routers with one ISP connection and a backup or VPN connection, and thats about it.This is probably a little shortsighted, but it’s a step forward from seeing the entire home as a single PC with a NAT to hide everything.
What I think the Working Group wants to avoid is letting the operators restrict what a user can and cannot do. It’s a classic struggle. The same thing happened with telephones, TVs, etc. I remember in the 1980s, at home we had this Cable splitter and amplifier that allowed us to run more than one TV in our home without the Cable company knowing, because if they did they would charge us more for two TVs. That was essentially the equivalent of the first NAT home gateways that allowed more than one PC. There has always been this tug-of-war between what the operator will provide as a supported configuration and what the users will make happen on their own if the ISP doesn’t provide it. We’re seeing a bit of that in the Working Group now.
Q: To build that structure, what part should actually be built with IPv6 ? Is IPv6 a necessary condition ? I think, some of the parts you have mentioned can be done using IPv4.
In addition to the arbitrary connection, we want to enable multiple ISPs, multihoming. This is were everything gets a little bit different between IPv6 and IPv4.
Within the IETF context, we are chartered to work on IPv6 only. But, we are not allowed to break IPv4, and we are chartered to operate in, as much as possible, an IP agnostic manner. So, if we develop something for IPv6, and if it happens to work with IPv4, fine, use it with IPv4. We're not going to define it in the working group, and somebody can write a different draft, or whatever.
If there is a choice like, "This is how we are going to do it in IPv6, but it's impossible to do it that way in IPv4", we are not going to cripple IPv6 in order to support IPv4's limitations. That's the point. We're not trying to take IPv4 and IPv6 and define both.. We're taking IPv6, and if it happens to work with IPv4, okay.
So, what we have developed connects all these routers together is a routing protocol. An IGP in your home. So far, it's been OSPF. There's been a recent discussion about IS-IS.
There's even a possibility that something else will come along. As the working group obtains more success, actually, you will end up with more people coming up with their own protocol. And at some point, the working group will have to make a choice.
But the fundamental part is, that there will be some control protocol between all those routers, that accepts the prefixes coming in from the multiple connections, assigns the prefixes internally so that all the routers will have their own local pool, and that those local pools use DHCPv6 or neighbor discovery to give address to the host. So it operates fully distributed. There will be no central home gateway that controls everything. In IPv6, each of those connections to the ISPs operate independently with one and other. If I have one ISP connection with a /56, that /56 gets advertised to all the routers that are in the home, and then the /64s for the individual links are pulled out of that /56 in an automated fashion, we have an algorithm and a proof and everything behind it.
So, that will happen per ISP uplink. If you have two uplinks, to ISPs, you end up with two delegated prefixes, two /64s, and every host gets two addresses. That's the fundamental difference between IPv4 and IPv6 here.
I can do all of that with IPv4, but I can't give one interface two IPv4 addresses.
Q: In order to come up with that kind of networking, each host has to have a IPv6 source address selection mechanism, DNS cache server selection, and a next hop selection. What kind of draft are there to address those issues ?
So, let me step into it one step at a time.
Once a host has two addresses, it has to select what address to use. And let's assume for a moment, that it selects a "good" source address. With some definition of "good".
There is a point, where we switch from a homenet scope to a scope of something like 6man(IPv6 maintenance working group) or mif(multiple interface working group). Clearly on the homenet side is, after the host has selected a source address, and sends a packet, we do source+dest routing in the home. To get it out the right exit, because there is BCP38 filtering, so the packet must go out the right exit.
There is a draft by Ole Troan and Lorenzo Colitti(http://tools.ietf.org/html/draft-troan-homenet-sadr), and there was also one by Fred Baker(http://tools.ietf.org/html/draft-baker-homenet-prefix-assignment).
The first is a base case, that has to happen for multiprefix multihoming to work at all, and we have good understanding and running code for it. Fred is taking it a little further, and saying "Maybe we even should route based on DSCP and flow labels". So, if you start bringing that into the routing protocol... it gets a bit more complicated and you start losing people..
I understand why all the reasons it's good. It is more about whether or not the community can accept going that far. So, that's under discussion.
But I think there is a clear consensus that at least we have source+dest routing.
Now, the next thing what your getting to, is a very current issue at the IETF, and it's multiple provisioning or multiple configuration domain. And that's classically been something that is discussed in mif and dhcp working groups. This is one of the project that our new area director Ted Lemon wants to solve. We discussed a lot at the last IETF. On last friday afternoon even.
And there is this question of, for example, when there is this iPhone here, it has multiple interfaces, it gets two different DNS servers, which one does it use ? Especially if one is scoped differently, which is a interesting problem in Japan :). But it can be seen elsewhere as well.
This is one of the things I talked about in the “hallways” of the last IETF, and I think it's bubbling up. There is a good chance we will end up with a combination of the mif WG architecture and homenet architecture. But the fundamental idea, if you take mif, what it's mostly focused on - a single device with multiple interfaces for which you can get multiple layer 3 configurations from. And the applications or the stack or the middleware has to deal with that.
In the homenet, what I want to be able to do with IPv6 is, each uplink also has information whether it's DNS or NTP servers whatever, or interface type like 3G, 4G, wireline, fiber whatever. Deutsche Telekom as well as some others, are interested in providing a colored arbitrary label for this prefix as well. So, this information gathered by home gateways, is gathered on a per prefix basis. And now I can take that prefix, and advertise it within the home, so even if you are in a device in two or three hops behind that uplink, all the information from the ISP about that network, whether it's a walled garden or it's not, for example, the associated DNS servers, all that stuff will be grouped into a single thing, and that is a IPv6 prefix.
If that information is coming all the way down to the host, and the home networks routing the packets so they match up, and it falls down to the source address that the host chooses. And the host also has every address that is assigned from a different prefix range, it's got the potential to use different configuration information. And that's irrespective of the number of layer 2 interfaces. We brought layer 3 configuration to layer 3. And now, you can start to make sense of it.
When it's layer 3 information but it's associated to layer 2, but you don't know if your tethering or if your not or whatever, it gets much more difficult. So, that’s the promises of the multi-prefix/multi-homing architecture, maybe we can do multi-configuration properly.
Now, this requires a lot of work. It's not too hard for the home network, the homenet piece is not hard. All we have to do, is take that bucket of stuff that comes in from the ISP as part of the interface, and make sure we carry it through the routing protocol, and down the DHCP or RAs to the host.
That's not so hard for us. And I think we can achieve that at homenet working group.
Teaching the host to remember all that information, provide to the applications proper APIs, that's actually the harder part. And it flips over into the mif working group, to make sure we bring it up right.
I think that the homenet working group is going to help put that problem space into the right perspective, because in the past it was driven too much by the mobile operator thinking about multiple layer 2 interfaces. And it was having problems. If you just step back and keep the layer 3 configuration at the prefix level, it make thing a lot more sane, I think. So, that I think you will be hearing more at the next IETF.
Q: I would like to have a future roadmap or milestones of the homenet working group. The milestone written in the working group charter page of the IETF web site ends on December 2012.
We have submitted updated milestones, so those are the original milestones that is there. The area directors have not clicked the right button, to prove it :).
This is a classic thing in most working groups in IETF. "Oh, we are going to finish it in a year", and when we start looking, we go, "Oh, it's going to be two years", and, "Oh, it' going to be three years". That’s the nature and the beast, often.
So, what we have now is, we have a homenet architecture document. We expect at least passed working group last call by the next IETF meeting. We put it up for a working group last call once, and we got a lot of comments, and hopefully we will have that finished.
In parallel we have a lot of solution documents, but as a principle we decided not to adopt them as working group documents until the architectural thing has passed. So, they've sort of been waiting. The next step would be selecting those.
And I think that the first would be if and which routing protocol. For some, it is just impossible to consider having a routing protocol in the home. In the event that the working group still chooses to have a routing protocol, will we stay with OSPF, or use IS-IS, or do we have both. The encouraging thing is, we have Open Source running code. Cisco has been funding it through technology fund initiatives. Open source version of OSPF running homenet. There has been one from couple of other individuals as well. And we've done some basic interoperability. So, that is coming.
The other pieces are service discoveries in home. If you consider as you have in a home a multiple subnet, but you want to see your streaming or whatever, how do you make that work across multiple subnets. We've got a couple of prototypes built, there are ways to do this without touching the standards necessarily. There is a separate work in dnsext working group that maybe forming, but they are focused more on enterprise environments. So, we are kind of still working out the best way to do this.
There are some other pieces, how much do we say about security or not on the edge. We may just say, "That's part of RFC6204, not our problem". There is actually some very good recent work, I am a big fan of the balanced security draft that came up recently in the v6ops working group from Ragnar Anfinsen (http://tools.ietf.org/html/draft-v6ops-vyncke-balanced-ipv6-security).
There are really three options when it comes to security at the edge of the home network. There is simple security, which is really the most simple minded – it looks the most like IPv4 today. There is advanced security, which I did with Eric Vyncke. Which is pushing far, especially 4 or 5 years ago, when we did it, it was like, "No way there will be a cloud connected gateway", of course there are now. And that makes the statement that simple firewalls do not provide the proper security. What you really need are dynamically updated traffic signatures, intrusion detection which you need to protect both directions. And you need something other than simple minded, "block all ports".
And balanced security, takes a sort of, well, balanced approach. Which is, "leave open most of the ports for incoming connections, but block the certain ones that are known to be bad".
So, it's kind of like three different levels. And we see, for example, Swisscom defaults to the balanced. Swisscom is also a co-author of the draft. And Altibox in Norway as well.
So, I have hoped for the balanced. The reason I don't like the simple security is because it looks so much like IPv4. It raises the same question as you asked before, "Oh, it works for IPv4, let's do it with IPv6 that way". And it's like, "Why do I do IPv6 at all then ?".
So, I like the balanced approach, but we have to do something with security. Border detection is a very tough problem, it's very important, it's protecting your WAN vs your LAN link. Here's where either you do have some product defined ports, and you restrict the user by saying, "Okay, this is where you plug the WAN, this is where you plug the LAN, everything else you can do on your own". Or, you can try to detect, for example, PPPoE is external, things like that. Or, you can go so far as to incorporate real security which we have one proposal from Michael Behringer from Cisco. It's part of what is sometimes called autonomic networking. Really interesting stuff in terms of secure automated bootstrapping and zero configuration. The problem homenet will have with this is, we are leaving the layer 3 pretty quickly. We're getting into boot strapping of the box. I would be great if we can rely on that, but we have within the IETF Internet Area much less of control of what ends up happening there. Because, you have to have secure IDs built into manufacturing process and all these kinds of things. I don't know if that's going to happen in the industry, but if does, GREAT! But I’m not sure IETF homenet along can make that happen.
So, that's kind of where we are. If you look at our five areas, routing, service and naming discovery, exposing the network by dynamic DNS updates, security, and border discovery.
Q: So, can I anticipate that, as regards routing, source address dependent or source address based routing would be the answers for the future home networks ? If it means that you have to change the current routing protocol, what kind of discussion will be there in the coming IETF meeting ?
Yes, the source plus dest routing, I forgot about that. That comes with the routing protocol.
What we have to do, there is two pieces. The routing protocol itself has to do the automatic prefix configuration, and carry the bucket information. But it also has to make sure that it can set up the forwarding tables in a way that's not just destination, but source plus destination.
And there is an easy way and a hard way. This is where you get into OSPF vs IS-IS. In OSPF, we managed to do it if we simplify and say, "The router that originally advertised the available prefix, the delegated prefix, is also the exit router". And also say that you are a totally stubby network, in OSPF terms. OSPF can then be used without terribly much extension. But if you go beyond, and go beyond a simple uplink case, and imagine this being used in a enterprise network, the change necessary to OSPF becomes much more significant.
That's one of Fred Bakers’ points. "You can just do this for the home, but if you want it to be generally useful, you are going to have to do all this, and you are going to create OSPF version 3.1 in the end. But if you do IS-IS, it would be easy".
Q: I would like to learn about the current trend of CGN.
I do know that there are more and more CGNs out there, certainly in mobile networks, and also appearing in wireline networks even in large ISPs.
I hear good thing and bad thing about CGN, but since I am a IPv6 guy, I hear bad things much more than good things :). So they call me when they say like, "Hey, look, here's another case where CGNs didn't work". Logging, for example, is one common complaint. That could be at the CGN itself, or on a website that didn’t record the ports being used, on the IP address.
The CGN itself is affecting the internet, and its end-to-end architecture for sure. I like things like MAP being standardized in the softwires WG, because it keeps the state out of the system.
IPv6 gets rid of the CGN entirely. This study shows the CGN cost over time.
The Benefits Mapping Address and Port (MAP) as Compared to DS-Lite
The Benefits of Mapping Address and Port (MAP) Technology
If you deploy IPv6, the CGN cost goes to nothing over time. Because the traffic moves to IPv6, and IPv4 traffic stops growing.
Q: I think that would be, "If people uses IPv6".
But they do.
For example, if you look at this graph, this is a large ISP in the U.S. This is from Google, almost 10% of users seen by Google, Yahoo, Facebook, and Bing is are now IPv6. All those users traffic will not go through the CGN for those websites, and any others that have IPv6.
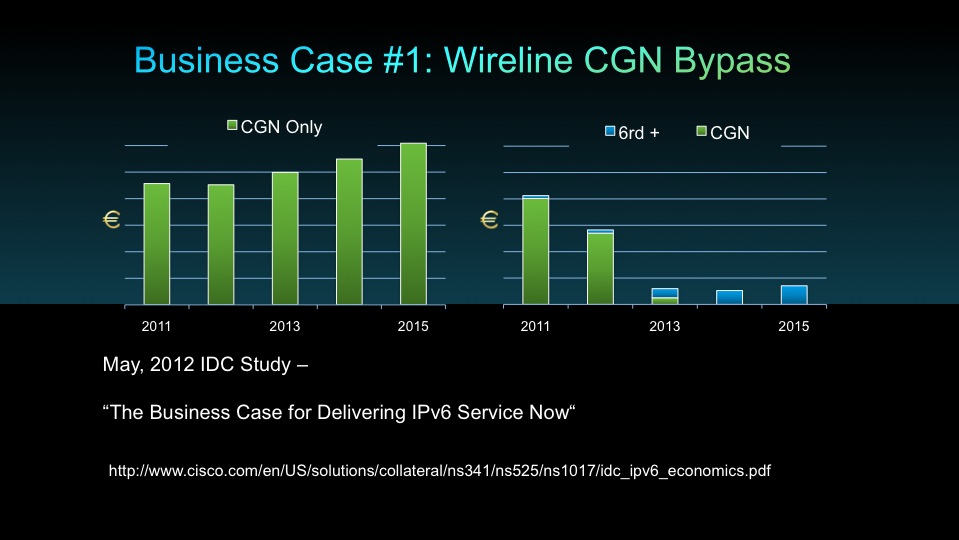
And if you look at Verizon Wireless, because it's newer equipment, 29% of traffic to Google is over IPv6. Almost 30% of that entire network base to Google is not going through a CGN anymore. It's completely bypassed, and Google (including youtube) plus facebook is a high percentage of traffic from an average user.
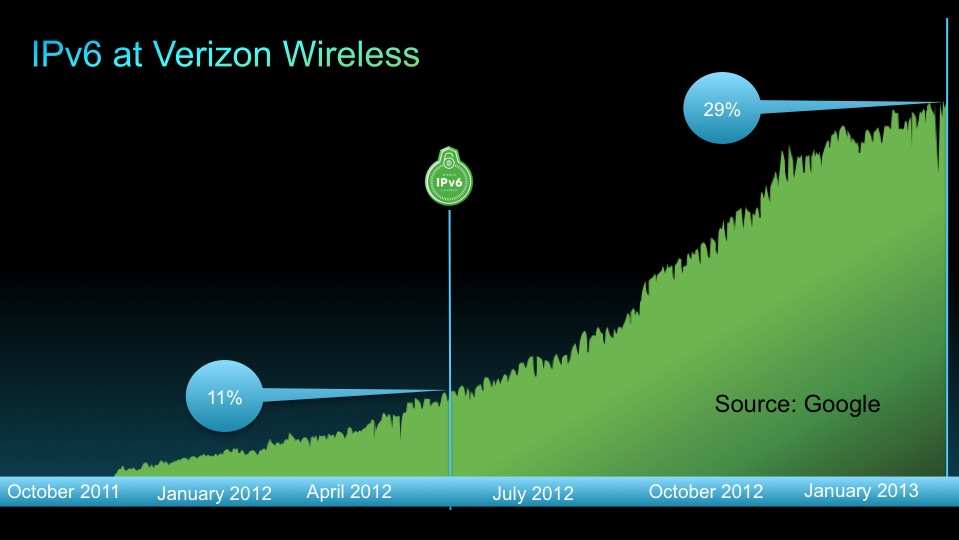
These are couple of universities, and again, if you look at Google plus Yahoo, etc, traffic, 63% of the traffic is IPv6. It's not because they are sitting there pinging IPv6, it's actual users from real providers.
Why this business model works, is because world IPv6 launch on last June, those big providers started advertising AAAA's.
When you look at the new networks like Verizon, or the others like AT&T, KDDI, or Free, you get glance of the future. When you look at the whole of the world, you say, "Oh NO, we're only at 1.3%". It's true, we're moving a mountain. But if you look at the new networks, you realize what's possible. The deployment can happen very fast.
If you had a ISP in their 5 year plan, in the next 5 years, either buying IPv4 addresses, or harvesting them from another part of the business, or do a massive renumbering, or buy CGNs would be needed. And they are looking at all these possibilities. The moment you decide to put in CGNs, you are changing the SLAs to the customer. You're changing the architecture, you're changing everything. So, the simple logic is to do IPv6 at the same time. That's the argument what worked with a lot of wirelines.
The overall cost difference between adding CGN alone and CGN plus IPv6 is almost negligible. Any ISP should at least hedging their bets to do both.
But in the existing wireless network, NAT is already baked in. The CGN is there, you have the logging, it all works, and it's just sort of built in from the start. Going in there is disrupting something, and that is always hard.
So, that's why you see it more in the Verizon Wireless LTE. LTE was a brand new network, and I suspect the new 4G networks in europe, etc, will be where you see IPv6 come in next.
When you see the new networks coming in, the IPv6 deployment issue is getting solved.
Q: Next is about softwire working group. Tell me what's going on in the working group.
There is a lot going on in the working group. What I've been most interested in of late, is MAP.
Stepping back though, softwires was chartered for IPv6 over IPv4 and IPv4 over IPv6.
The IPv6 over IPv4 case, while there has been dozens of possibilities, but we came down to two. One was reuse of L2TP, because it's already there. And that was sort of the quick and easy way.
And the other was 6rd. It was new technology. I was pushing this after I was no longer the director of the group. People were telling me, "Native IPv6 will be there tomorrow, stop working on these transition mechanisms", still, people have problems with native IPv6 in the access networks.
It's not so difficult in PPP or 1 to 1 VLAN models, just the DSL industry forgot about IPv6 when it developed their IPoE triple play stuff. So, 6rd has become a necessity.
6rd is also one of the things that helped the top two providers in terms of IPv6 access. I am a big fan of 6rd, as it was a necessary jump start to things.
So now the softwire working group is working on the flip side. In the beginning, we developed DS-Lite. Which is... Well, I am sorry that I helped create it now. Even the name of it...
Q: Do you mean that it is very confusing because its the same as Nintendo's DS-Lite ?
Oh, that's funny. I forgot about that. That wasn't the reason.
The history is, myself and Alain Durand, the co-chair of softwires, were at a bar in Paris when the ICANN meeting was in town there. He was working at a large cable operator in the US at the time and he said, "This is what I want to do", “I do not want to provision IPv4 to the home user, while still being able to give the user IPv4 service, so its still dual stack” so I said, "Great, that's still dual stack but it's lighter". And "Dual-Stack Lite" was born.
Sadly, any time you see "simple" or "light", it’s likely not simpler or lighter. It is lighter in terms of provisioning, but the problem is that it required taking all the NAT state in the residential gateway and centralizing it in the service provider network. That is the heavy part.
There is less IPv4 to enable, and you can see "Lite" as "Less IPv4 To Enable". But it came with the cost of the centralized NAT, which is quite heavy. As people deployed it, some ISPs started to realize, "I don't want that big centralized NAT, and we will leave that NAT in the edge", then came Lighweight 4over6 (http://tools.ietf.org/html/draft-cui-softwire-b4-translated-ds-lite) or Public 4over6 (http://tools.ietf.org/html/draft-ietf-softwire-public-4over6). Two names for largely the same thing.
And its still an end-to-end tunnel architecture as you could just use L2TP at this point. Its the same idea. Its just light because you're inventing it from scratch, so you don't have to support the PPP control plane or whatever.
But, its still fundamentally a point-to-point architecture, so you have some tunnel concentrator that can support a few hundred thousand, maybe a million users, all the traffic comes there and goes out, and you have to bind state to this tunnel, just like in L2TP. I noticed immediately like, "This is reinventing L2TP". I remember people saying, "No, No, No, this is lighter than L2TP". But its not. You ultimately ending up having point-to-point tunnels, keep-alives for the tunnels to make sure when they go down, there will be alerts on them, eventually its almost like an actual control plane.
So, this is my vision, and I much like better the stateless tunneling technologies, like 6rd and MAP. Here, you are getting away from this concentrating traffic to a single source, which ultimately is much better for the users.
Q: So, do you like A+P better than DS-Lite ?
Stateless A+P, yes. Much, much better.
It scales dramatically better than DS-Lite. For example, in our equipment, DS-Lite routes traffic through the ISM blade, so in ASR9K you get 14Gbps. In a single blade, using 24 line cards, you can do 240Gbps of IPv4 or IPv6 but also MAP. Because there is no state, and processed in line. This is the little trick. So, the ASR9010 chassis can do 1.68Tbps.
You don't have to worry about, "This CPE go match up with this AFTR, and this CPE match up with this AFTR". You just have to say, "All the CPE work with all the routers and you anycast to it".
Q: How about 4rd ?
4rd is OK.
I personally wished that we could chosen the name "4rd". It makes a lot of sense 6rd and 4rd. I loved it.
There was a problem in the working group, we had for a period of time, the leadership in the working group was pushing back any stateless solution. "DS-Lite is enough, we do not need anymore. We need to stop building new transition protocols". I think it was a premature decision, and it was a lot of work among the operators and vendors to break pass this.
Because the work wasn't allowed progress and come to consensus within the working group, individuals got very attached to their particular way about doing things. It got a lot more difficult over time. Because people get invested, in their marketing, in their implementation, in their own ideas.
That's what we end up with MAP-E, MAP-T, 4rd, dIVI, all these. They were all different flavors of largely the same thing. Without a forum to come together and compromise, we naturally ended up with big fights later.
4rd will likely exist as an experimental or informational document, MAP-T as well, maybe dIVI and IVI in some form. Thankfully the IETF has decided MAP-E as its standards track.
Q: Coin flip ?
Yes, flip the coin. That was really great.
Because sometimes, making a choice is more important than waiting for the perfect choice. We were down to percentages of difference, you know, like 1% difference between these two. Making a choice is better.
I am glad they made the choice. The name "MAP", don't personally love it. Would have liked the name to be "4rd". Would have been happy for Remi Despres to get his solution.
I didn't see a whole lot of need of the optimizations in 4rd-u. I think it is as a whole brilliant work, the question is at what point do you just stop optimizing, and ship. DS-Lite shipped too early. Even Lightweight 4over6 was too early. If I could do it all over again, I would have skipped these and gone straight to what we have in MAP.
One big success is agreeing on the MAP algorithm. I am really happy that we all agreed on this. The algorithm of the mapping is now common. After that, what was left was the beauty contest of how you format packets, it was really tiny details that were left to argue over beyond what was already quite beautiful. The algorithm mapping is fabulous work, it all goes back to SAM. The Stateless Address Mapping, from Remi Despres. It was his spark of brilliance, of 6rd as well, and what eventually became MAP.
That was the really important part, but like turning the crank in the IETF, you get all these tiny details. It becomes frustrating at times.
Q: The frustration you got from the softwire working group are already gone ?
Yes, most of it.
The biggest frustration was not having a place to talk about stateless IPv4 over IPv6. That was very frustrating. And finally the right thing was done. And we moved forward with the coin flip.
The coin flip was very interesting because it was not because flipping a coin between MAP-T versus MAP-E. It was flipping a coin over, "Do we ask this question, or that question, to the working group".
It was a coin flip over how to pose a question.
Do you pose a question over MAP-T verses MAP-E verses 4rd-u, or as MAP with a T and E variant verses 4rd-u. And the coin flip ended on, "Oh, there are 3 different things, MAP-T, MAP-E and 4rd". After that, it became very clear that everyone wanted MAP-E.
Because there were alliances forming, and things like that.
Q: Was it the first time IETF decided something using a coin flip ?
I think so.
Q: And I heard that the softwire working group chair has changed before the coin flip.
Yes. It was actually the IETF before. There was so much frustration on deciding MAP-E,MAP-T,4rd stuff. The previous working group chair didn’t come to a consensus call. I was furious about that, and I said among other things that perhaps a coin flip would be better. But I wasn't part of deciding or planning anything.
On the next IETF, we had a new chair, and a coin flip. So, somebody did something there.
I am not sure if the coin flip is becoming an official part of IETF or not.
Q: I have exhausted all my questions I have prepared. Thank you very much !
May. 2013
Japanese translated version