Skype大規模障害が収束。その規模と原因は?
24日午前7時頃(日本時間)にSkypeから「9割回復した」という発表が行われました。 これによると、今回の障害は外部の攻撃によるものではなさそうであるとのことでした。
「Another update: Skype stabilized」
原因の詳細は述べられていませんが、各種有料サービス利用者に無料通話サービス券を提供することが述べられています。 Skype社CEOのTony Bates氏による発表の動画も掲載されています。
動画の表情を見ると、憔悴しているのか寝不足であるように見えます。 この動画の5時間前に公開された動画よりも、随分疲れているようです。
障害の規模
Skype Journalに掲載されている記事(17.5 million: Skype restored dial tone twice as fast as in the 2007 outage)を見る限り、今回の障害規模は非常に大きかったようです。 一時は、ユーザ数がほぼゼロになっています。
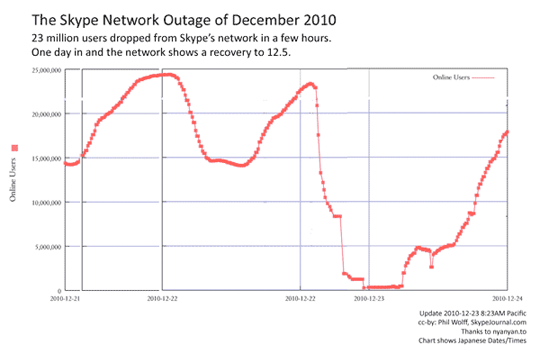
しかし、障害からの復旧は2007年に発生した大規模障害よりも2倍早かったとされています。
大規模障害の原因?
まず、前回の大規模障害である2007年8月16日の事例を見てみます。
「INTERNET Watch: Skype、障害はスーパーノード関連のバグと一斉ログインの負荷が原因」
INTERNET Watchの記事では、2007年の障害はWindows Updateなどによって大量のクライアントが一斉に再起動されることと、Skypeのバグが重なったことが原因だったと記述されています。
Skype日本オフィスの岩田真一ジェネラルマネージャーは、「スーパーノード」のコントロールにバグがあったことを説明した。Skypeのネットワークはユーザーが仮想的なグループに分けられており、その中からマシンスペックの高いものやグローバルIPアドレスを持っているものなど、一定の条件を満たす PCが自動的にスーパーノードに選ばれる(Skypeの全ユーザーのうち約1%)。スーパーノードはグループ内のユーザー情報を管理し、ユーザーはスーパーノードを通じて通話相手を検索する。
「スーパーノードになっているPCがWindows Updateなどで再起動されると、スーパーノードも切れることになる。通常、そのような状況を察知して自動的にスーパーノードの割合を調節する機構が働くが、今回はそこが働かないバグが見つかった」(岩田氏)。加えて、「減ったスーパーノードを追加させようとしたが、再起動後にSkypeのログインリクエストが集中し、その負荷にネットワークが耐えられなかったことも原因」としている。Windows Updateは毎月行なわれているが、今回に限って障害が発生したのは、この2つが重なったためだという。
このように、一般的なSkypeクライアントで条件を満たしているものが自律的にスーパーノードになるようですが、これらが一気に減ると他へと負荷がかかります。 その負荷が減ったスーパーノードへと集中することで、少なくなったスーパーノードが落ちてしまうという負の連鎖が発生します。
2010年12月に発生した障害の原因は、はっきりとは公表されていませんが、 スカイプ社のブログ(Skype Blog: Skype downtime today)でも、今回多くのスーパーノードがオフライン状態になったと発表されています。
Under normal circumstances, there are a large number of supernodes available. Unfortunately, today, many of them were taken offline by a problem affecting some versions of Skype.
今回も多くのSkypeが同時にオフラインになったために負の連鎖が発生して、スーパーノードが登場しても、一気にアクセスが集中して落ちてしまうという状況へと陥ったのかも知れません。 公開されている解決方法が「メガスーパーノード(mega-supernode)」を投入したり、一部のサービスを止めつつ他のサービスを復活するために活用するということからも、一度バランスが崩れたことによって定常的に過負荷な状態が発生するようになったのではないかと推測しています。
恐らく、メガスーパーノードというのは、一気に来るスーパーノードへの接続リクエストをバンバン受けることが出来る文字通りの巨大容量を持つスーパーノードなのだろうと思います。 一度、安定状態へと移行すれば、個別ユーザが利用しているSkypeソフトウェアがスーパーノードになっても負荷が集中することがなくなるので、定常状態に戻るという仕組みなのではないかと推測しています。 アナロジーとしては、車のバッテリーが切れたときに、他の車のバッテリーを持って来てエンジンをかけるところまでやって、一度エンジンがかかれば何とかなるというイメージなのかも知れません。
本当のところは知りませんが。。。
参考:Disruptive Telephony: Understanding Today's Skype Outage: Explaining Supernodes
Skypeメガスーパーノードのイメージキャラ
いかにも屈強そうな「mega-supernode」という表現が一部界隈で大ウケしていましたが、Skype Journalでイメージキャラが作成されていました(First picture of a Skype #MegaSuperNode)。 Marvelが提供しているキャラ作成Flash(Marvel.com : Create Your Own Superhero)を使って作ったもののようです。 擬人化というと、どうしても萌系の作風が多い印象があるので、アメコミ風の擬人化は新鮮でした。

試しに私も作ってみました。

でも、色々と越えられない壁を感じました。。。
最後に
昨日は、非常に多くの人々が「Skypeにつながらない!」「Skypeにログインできない!」「Skypeが使えない!」と困っていましたが、Skypeを使っているユーザが多いことを実感できる一日でした。
今回の障害の原因は、まだ正式発表されていません。 しかし、何となく「雪崩現象(もしくは連鎖反応?)を起こしちゃったのかな?」と思えました。
「みんなで何とか頑張って支える大規模分散システム」というのは、何とか頑張れるうちは良くても、何らかのきっかけで支えきれない部分が発生すると、その部分が過負荷となって他の部分を襲うことによってシステム全体が崩壊するという現象を見せつけられた事例なのかも知れません。
おまけ:IPv4アドレス枯渇とSkype
NATの裏側にいるクライアント同士の橋渡し役になっているSkypeのスーパーノードですが、IPv4アドレスが枯渇してISPがLSN(Large Scale NAT, or Carrier Grade NAT, or Multi-User NAT, whatever...)を運用するようになれば、スーパーノードになれるクライアントが一気に減る可能性があります。
IPv4アドレスのIANAプールは来年早期に枯渇しそうですが、来年中は恐らく今まで通りの運用が続くISPが多そうであるため、実際に変化がLSNの運用が各所で開始されるのが2012年ぐらいだと考えると、その時期にまたSkypeが不安定化する可能性もありそうだと感じました。
IPv4グローバルアドレスを持っていてスーパーノードと成り得るクライアントが徐々に減る事を考えると、SkypeのようなP2Pシステムが2012年以降存続するには、グローバルIPアドレスを利用できるIPv6へと多くのユーザが移行することが必要となりそうです。 ISP規模でのNAT環境でIPv4を利用しつつ、IPv6へと移行しないユーザが増えれば増えるほど、今回のような問題が発生しやすくなるためです。 そのため、IPv6がどれだけの速度で普及するのかと、Skypeの安定度は無関係ではなさそうだと個人的に考えています。
そう思うと、そのうちSkype社はIPv6対応とIPv6のプロモーションを開始するのかも知れないと思いました。 SkypeのソフトウェアだけがIPv6対応するのでは不十分で、多くのユーザがIPv6を使ってくれるようにならないと、恐らくSkype社は困りそうです(逆に考えると、Skype社が常に巨大なメガスーパーノード的サーバを運営し続けなければならない状態に陥る可能性もありそうです)。
このような感じで、一般的なインターネットユーザとしてはIPv6への移行を急ぐメリットは少なくても、多くのユーザがIPv6への移行してくれないと困るからプロモーションする組織というのが来年以降登場しそうだと妄想する今日この頃です。
今回の事件とは全く関係ありませんが「グローバルIPアドレスを必要とする」という部分で連想しました。
関連
最近のエントリ
- Interop 2023のShowNetバックボーン詳解
- Interop Tokyo 2023 ShowNet取材動画
- 「ピアリング戦記 - 日本のインターネットを繋ぐ技術者たち」を書きました!
- 1.02Tbpsの対外線!400GbE相互接続も - Interop ShowNet 2022
- Alaxala AX-3D-ViewerとAX-Sensor - Interop 2022
- SRv6を活用し、リンクローカルIPv6アドレスだけでバックボーンのルーティング - Interop ShowNet 2022
過去記事
